XML Parsing and Transformation in JavaScript Applications
fast-xml-parser, xml-js, and xml2js are npm packages designed to handle XML data within JavaScript environments. They allow developers to parse XML strings into JSON objects and convert JSON back into XML strings. xml2js is the legacy standard with a long history, fast-xml-parser focuses on high performance and validation, and xml-js offers a lightweight alternative with a specific element-centric structure. These tools are essential when integrating with SOAP APIs, RSS feeds, SVG manipulation, or legacy enterprise systems that rely on XML.
Npm Package Weekly Downloads Trend
Github Stars Ranking
Stat Detail
XML Parsing in JavaScript: fast-xml-parser vs xml-js vs xml2js
When working with XML in JavaScript — whether you are consuming a SOAP API, reading an RSS feed, or processing an SVG file — you need a reliable way to convert XML text into usable JavaScript objects. The three most common tools for this job are fast-xml-parser, xml-js, and xml2js. While they all solve the same core problem, they differ significantly in speed, API design, and how they represent data.
⚡ Performance and Validation Capabilities
Speed matters when you are processing large files or handling many requests. fast-xml-parser is built specifically for performance and includes a built-in XML validator. The other two focus more on compatibility and ease of use.
fast-xml-parser uses a pure JavaScript implementation optimized for speed. It can validate XML during parsing to ensure the input is well-formed.
// fast-xml-parser: Parse with validation
const { XMLParser } = require("fast-xml-parser");
const parser = new XMLParser({
ignoreAttributes: false,
validate: true // Built-in validation
});
const result = parser.parse(xmlString);
xml-js prioritizes a clean conversion process but does not include a dedicated validation step in its main API. It relies on the underlying parser to throw errors on malformed XML.
// xml-js: Basic conversion
const convert = require('xml-js');
const result = convert.xml2js(xmlString, {
compact: false,
spaces: 4
});
// No explicit validation flag available in options
xml2js is the oldest of the three. It is stable but generally slower than fast-xml-parser on large datasets. It does not have a built-in validation flag either.
// xml2js: Parse with callback
const parseString = require('xml2js').parseString;
parseString(xmlString, (err, result) => {
if (err) throw err;
// result is the JSON object
});
🗂️ Data Structure: How XML Becomes JSON
The way these libraries map XML tags to JSON properties changes how you write the rest of your code. xml2js and fast-xml-parser allow custom mapping, while xml-js has a more rigid structure.
fast-xml-parser gives you control over how attributes and text nodes are named. You can flatten the structure to make it easier to access values.
// fast-xml-parser: Custom attribute name
const parser = new XMLParser({
ignoreAttributes: false,
attributeNamePrefix: "@_"
});
// <book id="1">Title</book> becomes:
// { "book": { "@_id": "1", "#text": "Title" } }
xml-js uses a specific format where every node has a name, type, and elements array by default (non-compact mode), or a very dense object in compact mode.
// xml-js: Non-compact structure
const result = convert.xml2js(xmlString, { compact: false });
// <book id="1">Title</book> becomes:
// { type: 'element', name: 'book', attributes: { id: '1' }, elements: [...] }
xml2js wraps text content in a special array by default, which often surprises new users. You must configure it to get clean strings.
// xml2js: Default behavior
parseString(xmlString, (err, result) => {
// <book>Title</book> becomes:
// { "book": [ "Title" ] }
// Note the array wrapper
});
🔄 Converting Back: JSON to XML
Sometimes you need to generate XML from JavaScript objects, such as when building a SOAP request or an SVG file dynamically.
fast-xml-parser includes a dedicated XMLBuilder class that is fast and configurable.
// fast-xml-parser: Build XML
const { XMLBuilder } = require("fast-xml-parser");
const builder = new XMLBuilder({
ignoreAttributes: false,
attributeNamePrefix: "@_"
});
const xmlOutput = builder.build(jsonObject);
xml-js provides a symmetric js2xml function that mirrors its parsing logic.
// xml-js: Build XML
const xmlOutput = convert.js2xml(jsonObject, {
compact: false,
spaces: 4
});
xml2js uses a Builder class to reconstruct XML. It requires you to remember the structure it created during parsing to ensure it builds back correctly.
// xml2js: Build XML
const Builder = require('xml2js').Builder;
const builder = new Builder();
const xmlOutput = builder.buildObject(jsonObject);
🛠️ Configuration and Ease of Use
Developer experience varies based on how much setup is required to get a usable output.
fast-xml-parser requires instantiating a class. This allows for reusable instances but adds a bit of boilerplate compared to a simple function call.
// fast-xml-parser: Class instantiation
const parser = new XMLParser(options);
const result = parser.parse(xml);
xml-js uses a simple function call. It is very straightforward for one-off conversions.
// xml-js: Function call
const result = convert.xml2js(xml, options);
xml2js relies on callbacks by default, which can lead to "callback hell" if not wrapped in a Promise. Newer versions support promises, but the API feels older.
// xml2js: Callback style
parseString(xml, (err, result) => {
if (err) handle(err);
use(result);
});
// Promise style (requires wrapping or util.promisify)
const parse = util.promisify(parseString);
const result = await parse(xml);
🌐 Real-World Scenarios
Scenario 1: High-Volume RSS Feed Aggregator
You are processing thousands of RSS feeds every minute. Performance is critical.
- ✅ Best choice:
fast-xml-parser - Why? It is significantly faster and uses less memory. The built-in validation prevents bad feeds from breaking your pipeline.
Scenario 2: Legacy Enterprise SOAP Client
You are maintaining an older Node.js service that talks to a banking API.
- ✅ Best choice:
xml2js - Why? If the codebase already uses it, stick with it to avoid refactoring risks. It handles complex XML schemas reliably, even if it is slower.
Scenario 3: Simple Configuration File Reader
You need to read a small XML config file at startup.
- ✅ Best choice:
xml-js - Why? The setup is minimal. For small files, the speed difference is negligible, and the code is clean.
📌 Summary Table
| Feature | fast-xml-parser | xml-js | xml2js |
|---|---|---|---|
| Primary Focus | Speed & Validation | Simplicity | Legacy Compatibility |
| API Style | Class-based | Function-based | Callback/Promise |
| Validation | ✅ Built-in | ❌ No | ❌ No |
| Text Handling | Configurable | Structured | Array-wrapped (default) |
| Maintenance | Active | Moderate | Mature / Stable |
💡 Final Recommendation
For new projects, fast-xml-parser is the strongest candidate. It offers the best performance, active maintenance, and modern features like validation. It saves you from writing extra code to check if the XML is valid.
Use xml-js if you want a lightweight dependency and prefer its specific data structure for your use case. It is a solid middle ground.
Reserve xml2js for legacy maintenance. While it is not officially deprecated, it is no longer the best tool for the job in terms of speed and developer experience. Moving to a newer library is recommended when refactoring old code.
How to Choose: fast-xml-parser vs xml-js vs xml2js
- fast-xml-parser:
Choose
fast-xml-parserif performance is your top priority or if you need strict XML validation. It is the best fit for high-throughput scenarios like processing large RSS feeds or handling frequent API requests. It also supports modern features like X2J and J2X conversion with extensive configuration options for attribute handling. - xml-js:
Choose
xml-jsif you prefer a simple, element-centric data structure that closely mirrors the XML hierarchy. It is suitable for smaller projects where bundle size matters slightly more than raw speed, and you need a straightforward conversion without complex validation requirements. - xml2js:
Choose
xml2jsonly if you are maintaining a legacy codebase that already depends on it. It is a mature library but lacks the performance optimizations and modern feature set of newer alternatives. For new projects, it is generally better to evaluatefast-xml-parserinstead due to better active maintenance and speed.
Popular Comparisons
README for fast-xml-parser
fast-xml-parser

Validate XML, Parse XML to JS Object, or Build XML from JS Object without C/C++ based libraries and no callback.
- Validate XML data syntactically. Use detailed-xml-validator to verify business rules.
- Parse XML to JS Objects and vice versa
- Common JS, ESM, and browser compatible
- Faster than any other pure JS implementation.
It can handle big files (tested up to 100mb). XML Entities, HTML entities, and DOCTYPE entites are supported. Unpaired tags (Eg <br> in HTML), stop nodes (Eg <script> in HTML) are supported. It can also preserve Order of tags in JS object
Flexible-XML-Parser is 2 times faster than this library and allows to deal with incomplete XML/HTML. Output is highly customizable. Build whatever you want. So if you're fine with some extra configuration then try it out.
Your Support, Our Motivation
Please join Discord community for pre release announcements and discussions. This will prevent us to release breaking changes.
Financial Support
Sponsor this project


This is a donation. No goods or services are expected in return. Any requests for refunds for those purposes will be rejected.
Users


















The list of users are mostly published by Github or communicated directly. Feel free to contact if you find any information wrong.
More about this library
How to use
To use as package dependency
$ npm install fast-xml-parser
or
$ yarn add fast-xml-parser
To use as system command
$ npm install fast-xml-parser -g
To use it on a webpage include it from a CDN
Example
As CLI command
$ fxparser some.xml
In a node js project
const { XMLParser, XMLBuilder, XMLValidator} = require("fast-xml-parser");
const parser = new XMLParser();
let jObj = parser.parse(XMLdata);
const builder = new XMLBuilder();
const xmlContent = builder.build(jObj);
In a HTML page
<script src="path/to/fxp.min.js"></script>
:
<script>
const parser = new fxparser.XMLParser();
parser.parse(xmlContent);
</script>
Bundle size
| Bundle Name | Size |
|---|---|
| fxbuilder.min.js | 6.5K |
| fxparser.min.js | 20K |
| fxp.min.js | 26K |
| fxvalidator.min.js | 5.7K |
Documents
| v3 | v4 and v5 | v6 |
| documents |
note:
- Version 6 is released with version 4 for experimental use. Based on its demand, it'll be developed and the features can be different in final release.
- Version 5 has the same functionalities as version 4.
Performance
negative means error
XML Parser
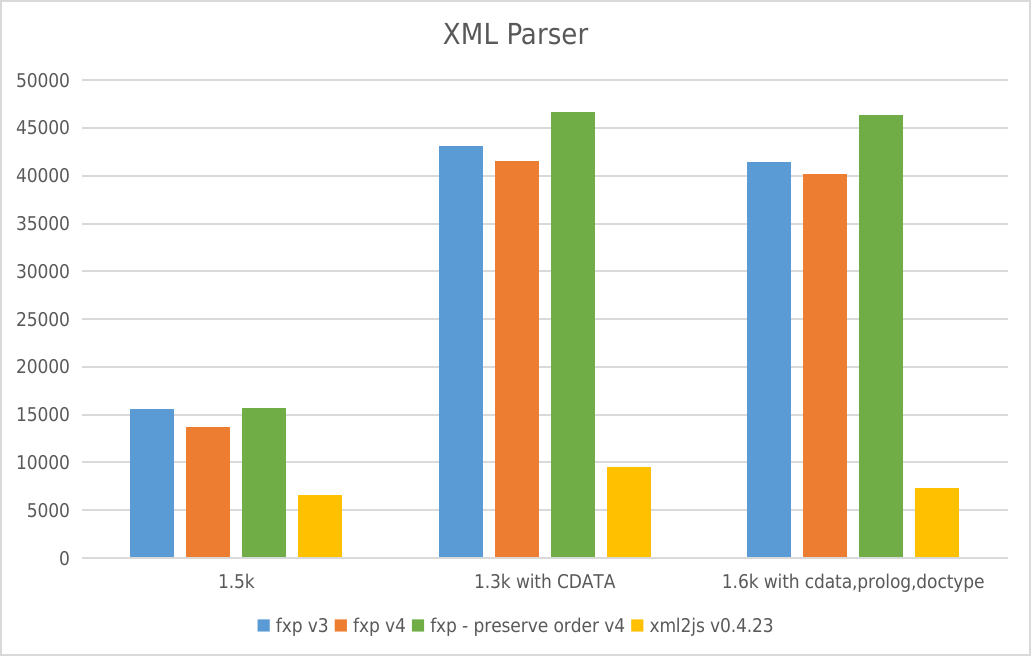
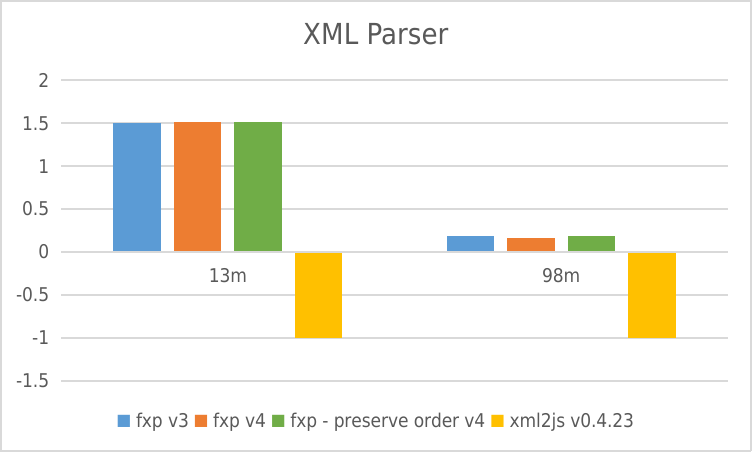
- Y-axis: requests per second
- X-axis: File size
XML Builder
 * Y-axis: requests per second
* Y-axis: requests per second
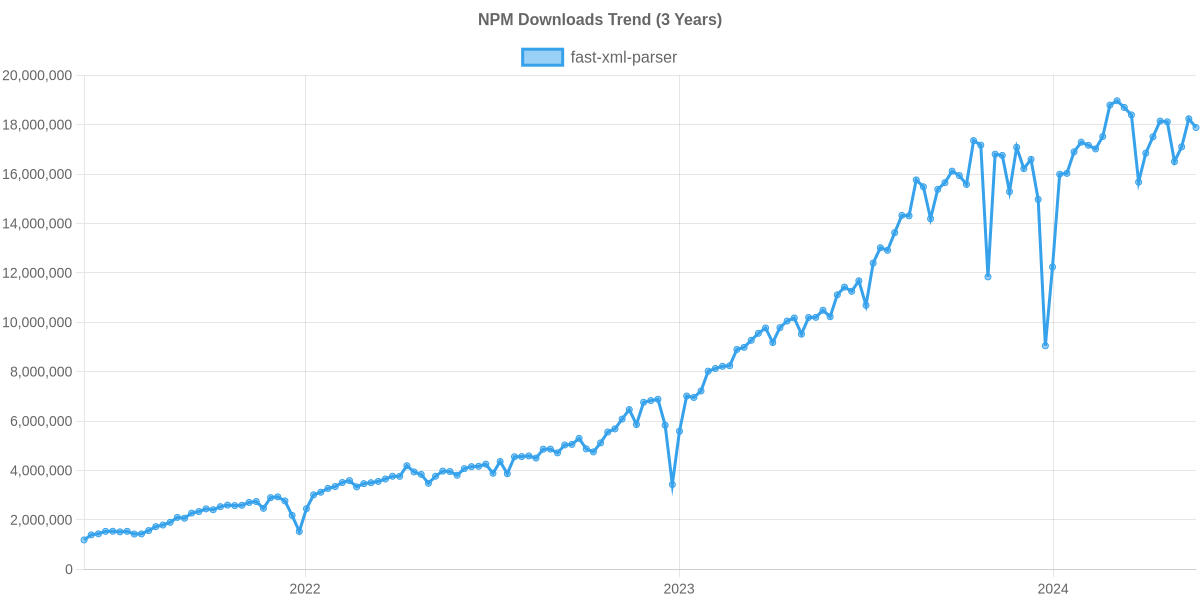
Usage Trend
Usage Trend of fast-xml-parser
Supporters
Contributors
This project exists thanks to all the people who contribute. [Contribute].

Backers from Open collective
Thank you to all our backers! 🙏 [Become a backer]

License
- MIT License
