XML Processing Strategies in JavaScript Applications
These libraries handle XML data in JavaScript, but they serve different roles. Some focus on parsing XML into JSON objects, others build XML from scratch, and some provide a DOM interface similar to browsers. fast-xml-parser and xml2js convert XML to JSON for easy manipulation. xmlbuilder specializes in generating XML structures. xmldom offers a DOM API for XML. libxmljs and libxmljs2 use native bindings for high performance but require Node.js. Choosing the right tool depends on whether you need speed, browser support, or DOM compatibility.
Npm Package Weekly Downloads Trend
Github Stars Ranking
Stat Detail
XML Processing in JavaScript: Parsers, Builders, and DOM Implementations
Working with XML in JavaScript requires choosing between speed, compatibility, and API style. The six packages here cover three main areas: parsing XML into data, building XML from data, and manipulating XML via DOM methods. Some rely on native code for performance, while others run purely in JavaScript. Let's compare how they handle real-world tasks.
⚙️ Parsing Engine: Native Bindings vs Pure JavaScript
The core difference lies in how these libraries process XML. Native bindings offer speed but limit where you can run your code. Pure JavaScript works everywhere but may be slower on massive files.
libxmljs uses native C++ bindings to libxml2.
- Requires compilation via node-gyp.
- Fails in browsers or serverless environments without specific binaries.
// libxmljs: Native parsing
const libxmljs = require("libxmljs");
const xmlDoc = libxmljs.parseXmlString('<root><item>1</item></root>');
console.log(xmlDoc.toString());
libxmljs2 is a maintained fork of libxmljs.
- Same native requirements as the original.
- Better long-term support for Node.js versions.
// libxmljs2: Native parsing (fork)
const libxmljs2 = require("libxmljs2");
const xmlDoc = libxmljs2.parseXmlString('<root><item>1</item></root>');
console.log(xmlDoc.toString());
fast-xml-parser is written entirely in JavaScript.
- No compilation needed.
- Runs in browsers, Node.js, and Deno.
// fast-xml-parser: Pure JS parsing
const { XMLParser } = require("fast-xml-parser");
const parser = new XMLParser();
const result = parser.parse('<root><item>1</item></root>');
console.log(result);
xml2js is also pure JavaScript.
- Very stable and widely adopted.
- Uses callbacks by default but supports promises.
// xml2js: Pure JS parsing
const { parseStringPromise } = require("xml2js");
const result = await parseStringPromise('<root><item>1</item></root>');
console.log(result);
xmldom provides a DOM parser in pure JavaScript.
- Mimics browser
DOMParser. - Deprecated in favor of
@xmldom/xmldom.
// xmldom: DOM parsing
const { DOMParser } = require("xmldom");
const doc = new DOMParser().parseFromString('<root><item>1</item></root>', 'text/xml');
console.log(doc.toString());
📦 Data Output: JSON Objects vs DOM Trees
How you access data matters. JSON is easier for JavaScript logic. DOM trees allow XPath and node traversal.
fast-xml-parser converts XML directly to JSON objects.
- Attributes and tags become properties.
- Easy to integrate with modern app state.
// fast-xml-parser: JSON output
const parser = new XMLParser();
const json = parser.parse('<user id="1">Alice</user>');
// { user: { "@_id": "1", "#text": "Alice" } }
xml2js also outputs JSON but with a different structure.
- Often wraps text in arrays.
- Configurable via options.
// xml2js: JSON output
const result = await parseStringPromise('<user id="1">Alice</user>');
// { user: { $: { id: "1" }, _: "Alice" } }
xmldom returns a DOM tree.
- Use
getElementsByTagNameto find nodes. - Closer to browser API but heavier.
// xmldom: DOM output
const doc = new DOMParser().parseFromString('<user id="1">Alice</user>', 'text/xml');
const node = doc.getElementsByTagName('user')[0];
console.log(node.getAttribute('id'));
libxmljs and libxmljs2 return native DOM-like objects.
- Support XPath queries directly.
- Faster for complex queries on large documents.
// libxmljs2: XPath query
const xmlDoc = libxmljs2.parseXmlString('<root><item id="1"/></root>');
const nodes = xmlDoc.findall('//item[@id]');
console.log(nodes.length);
🛠️ Building XML: Generation Tools
Some projects need to create XML, not just read it. Dedicated builders simplify this task.
xmlbuilder is designed specifically for creating XML.
- Chainable API for nodes and attributes.
- Does not parse existing XML.
// xmlbuilder: Creating XML
const builder = require("xmlbuilder");
const xml = builder.create('root')
.ele('item', { id: "1" }).txt('Value').up()
.end();
fast-xml-parser includes a builder component.
- Converts JSON back to XML.
- Keeps parsing and building in one package.
// fast-xml-parser: Building from JSON
const { XMLBuilder } = require("fast-xml-parser");
const builder = new XMLBuilder();
const xml = builder.build({ root: { item: "Value" } });
xml2js also has a Builder class.
- Complements its parser.
- Useful if you already use
xml2jsfor parsing.
// xml2js: Building from JSON
const { Builder } = require("xml2js");
const builder = new Builder();
const xml = builder.buildObject({ root: { item: "Value" } });
⚠️ Maintenance and Security Status
Security and active maintenance are critical for XML libraries due to vulnerabilities like XXE.
xmldom is officially deprecated.
- The npm page advises using
@xmldom/xmldom. - Security fixes may not land in the unscoped version.
// xmldom: Deprecation warning
// Do not use in new projects. Switch to @xmldom/xmldom.
libxmljs has had periods of low activity.
- Native dependencies can break with Node updates.
libxmljs2is the recommended fork for stability.
// libxmljs vs libxmljs2
// Prefer libxmljs2 for ongoing Node.js compatibility.
fast-xml-parser and xml2js are actively maintained.
- Pure JS means fewer breakages during Node upgrades.
- Regular security patches for parsing logic.
// fast-xml-parser & xml2js
// Both are safe choices for long-term projects.
📊 Summary: Capabilities at a Glance
| Package | Environment | Output Type | Building Support | Maintenance |
|---|---|---|---|---|
fast-xml-parser | Any (Pure JS) | JSON | ✅ Yes | ✅ Active |
libxmljs | Node (Native) | DOM/XPath | ❌ No | ⚠️ Stalled |
libxmljs2 | Node (Native) | DOM/XPath | ❌ No | ✅ Active Fork |
xml2js | Any (Pure JS) | JSON | ✅ Yes | ✅ Active |
xmlbuilder | Any (Pure JS) | XML String | ✅ Yes (Only) | ✅ Active |
xmldom | Any (Pure JS) | DOM | ❌ No | ❌ Deprecated |
💡 Final Recommendation
fast-xml-parser is the best all-rounder for modern apps. It handles parsing and building with high speed and no native dependencies. Use it for APIs, configuration files, and data exchange.
xml2js is a solid alternative if you need legacy compatibility. It is stable and well-understood, though slightly slower than fast-xml-parser.
libxmljs2 is the choice for heavy server-side workloads. Use it if you need XPath or native performance and can guarantee a Node.js environment.
xmlbuilder shines when generating complex XML documents. Pair it with a parser if you need round-trip support.
xmldom should be avoided. Switch to @xmldom/xmldom if you strictly need DOM methods in JavaScript.
Final Thought: For most frontend and full-stack developers, pure JavaScript solutions like fast-xml-parser offer the best balance of safety, speed, and deployment flexibility.
How to Choose: fast-xml-parser vs libxmljs vs libxmljs2 vs xml2js vs xmlbuilder vs xmldom
- fast-xml-parser:
Choose
fast-xml-parserwhen you need high performance in a pure JavaScript environment. It handles both parsing and building without native dependencies, making it safe for browsers and serverless functions. It supports validation and complex XML features like attributes and tags. This is ideal for modern APIs where speed and security matter. - libxmljs:
Choose
libxmljsonly if you are locked into a Node.js environment and require native libxml2 features. Be aware that it requires compilation and may fail on systems without build tools. It is not suitable for frontend or serverless deployments. Considerlibxmljs2instead for better maintenance support. - libxmljs2:
Choose
libxmljs2if you need native XML processing in Node.js but want a more actively maintained fork. It offers the same performance benefits aslibxmljswith fewer stagnation risks. Like its predecessor, it cannot run in browsers due to native bindings. Use this for heavy-duty server-side XML workflows. - xml2js:
Choose
xml2jsfor stable, proven XML-to-JSON conversion in Node.js or bundled web apps. It has been around for years and handles most standard XML structures reliably. The API is callback-based but supports promises. It is a safe default for legacy systems or projects prioritizing stability over raw speed. - xmlbuilder:
Choose
xmlbuilderwhen your primary task is generating XML documents from JavaScript objects. It provides a clean chainable API for constructing nodes and attributes. It does not focus on parsing, so pair it with a parser if you need bidirectional support. This is best for creating feeds, sitemaps, or SOAP requests. - xmldom:
Avoid
xmldomfor new projects as it is deprecated in favor of@xmldom/xmldom. It mimics the browser DOM API for XML, which is useful for XPath or DOM manipulation. If you must use it, know that security patches may be delayed. Only select this if you strictly require DOM methods in a Node environment.
Popular Comparisons
README for fast-xml-parser
fast-xml-parser

Validate XML, Parse XML to JS Object, or Build XML from JS Object without C/C++ based libraries and no callback.
- Validate XML data syntactically. Use detailed-xml-validator to verify business rules.
- Parse XML to JS Objects and vice versa
- Common JS, ESM, and browser compatible
- Faster than any other pure JS implementation.
It can handle big files (tested up to 100mb). XML Entities, HTML entities, and DOCTYPE entites are supported. Unpaired tags (Eg <br> in HTML), stop nodes (Eg <script> in HTML) are supported. It can also preserve Order of tags in JS object
Flexible-XML-Parser is 2 times faster than this library and allows to deal with incomplete XML/HTML. Output is highly customizable. Build whatever you want. So if you're fine with some extra configuration then try it out.
Your Support, Our Motivation
Please join Discord community for pre release announcements and discussions. This will prevent us to release breaking changes.
Financial Support
Sponsor this project


This is a donation. No goods or services are expected in return. Any requests for refunds for those purposes will be rejected.
Users


















The list of users are mostly published by Github or communicated directly. Feel free to contact if you find any information wrong.
More about this library
How to use
To use as package dependency
$ npm install fast-xml-parser
or
$ yarn add fast-xml-parser
To use as system command
$ npm install fast-xml-parser -g
To use it on a webpage include it from a CDN
Example
As CLI command
$ fxparser some.xml
In a node js project
const { XMLParser, XMLBuilder, XMLValidator} = require("fast-xml-parser");
const parser = new XMLParser();
let jObj = parser.parse(XMLdata);
const builder = new XMLBuilder();
const xmlContent = builder.build(jObj);
In a HTML page
<script src="path/to/fxp.min.js"></script>
:
<script>
const parser = new fxparser.XMLParser();
parser.parse(xmlContent);
</script>
Bundle size
| Bundle Name | Size |
|---|---|
| fxbuilder.min.js | 6.5K |
| fxparser.min.js | 20K |
| fxp.min.js | 26K |
| fxvalidator.min.js | 5.7K |
Documents
| v3 | v4 and v5 | v6 |
| documents |
note:
- Version 6 is released with version 4 for experimental use. Based on its demand, it'll be developed and the features can be different in final release.
- Version 5 has the same functionalities as version 4.
Performance
negative means error
XML Parser
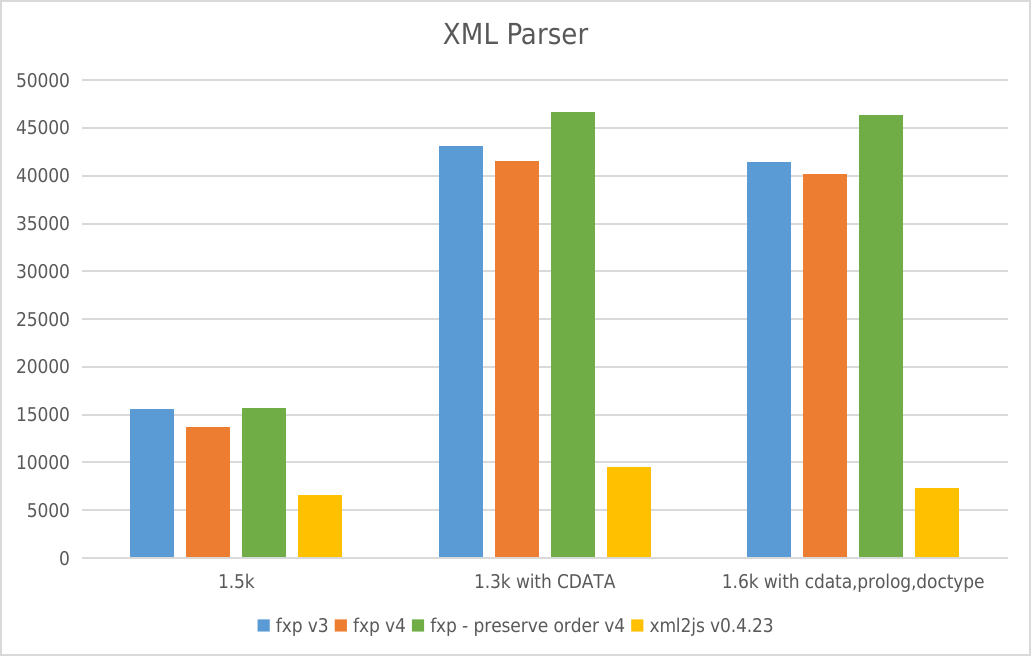
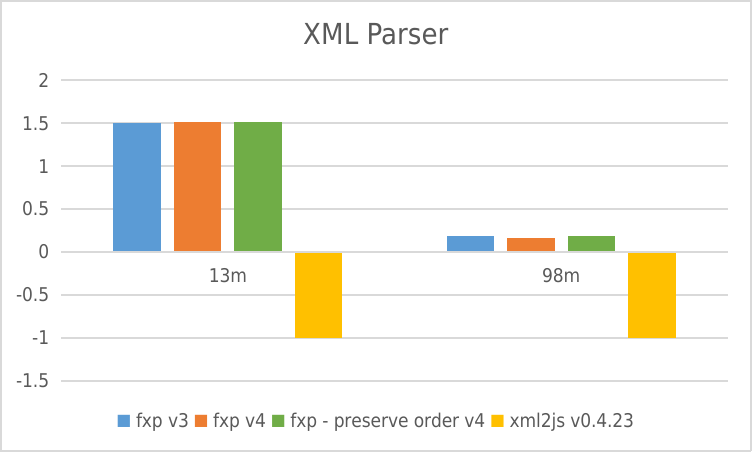
- Y-axis: requests per second
- X-axis: File size
XML Builder
 * Y-axis: requests per second
* Y-axis: requests per second
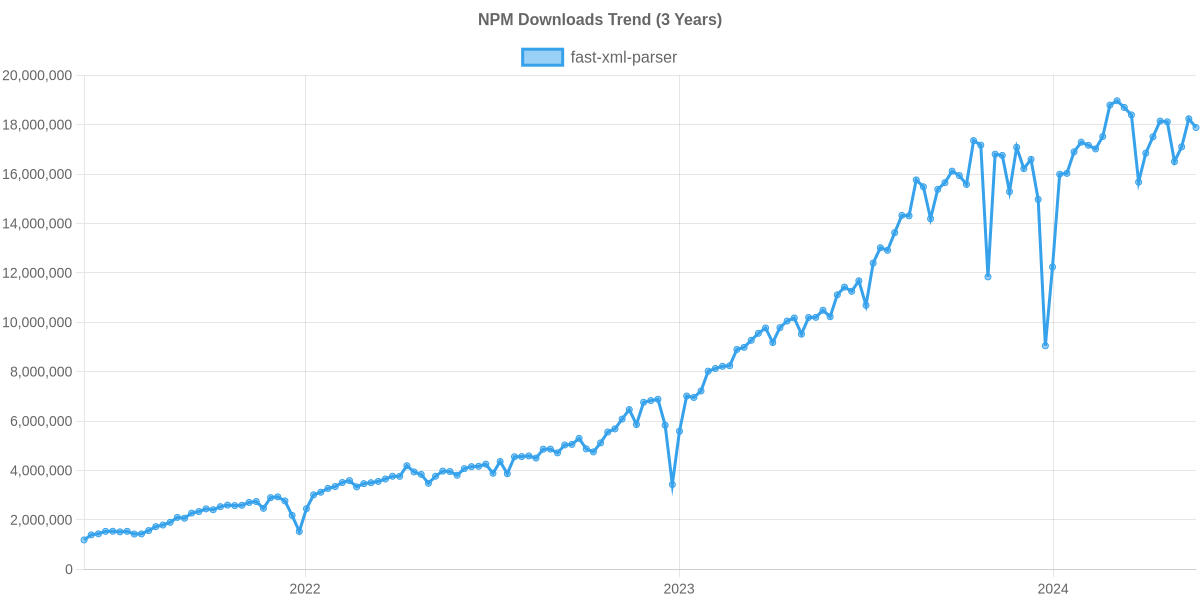
Usage Trend
Usage Trend of fast-xml-parser
Supporters
Contributors
This project exists thanks to all the people who contribute. [Contribute].

Backers from Open collective
Thank you to all our backers! 🙏 [Become a backer]

License
- MIT License
